Visual Cues for Text
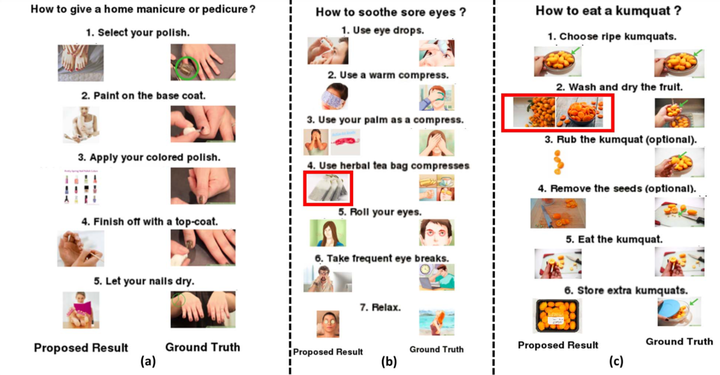
In this project, following multi-stage framework was developed to provide visual aid for a sequence of text based instructions in the form of coherent images associated with each of them - (a) For each instruction, visualisable phrases consisting of head action verbs and noun phrases are mined using standard practices like POS tagging, Dependency parsing and Co-reference resolution. (b) For each visualisable phrase, an API query is made to retrieve a set of images from a dataset crawled from sources such as WikiHow, Flickr, Google etc. Phrases and images together dictate the action being conducted in the instruction. (c) Across instructions sharing common information in the form of latent/non-latent entities, coherency is maintained using a graph based matching method utilising Dijkstra’s algorithm. A user study was conducted to validate improvement in understanding of text instructions and resemblance to actual ground truth.
Abhinav Jain
Research Engineer
My research interests include computer vision, machine learning and deep reinforcement learning.
Publications
Coherent Visual Description of Textual Instructions
