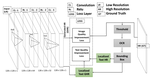
Scanned PDF-to-HTML Conversion

In practice, scanned PDF documents are converted into consumable representations (HTML/JSON) to drive structured data extraction. However, poor quality document images suffer from low token fidelity when an OCR engine such as Tessearct is used for token extraction. To remedy this, we leveraged deep learning based solutions for document quality enhancement and delivered the same for public release as part of IBM’s Watson API. We formulated a novel `Text Quality Improvement Loss’ for the standard super-resolution convolutional neural network (SRCNN) to generate high-resolution text images. The proposed framework identifies text regions from images and minimizes additional MSE between such localised regions on top of the standard MSE, enforced by Single Image Super Resolution frameworks. This results in simultaneous optimisation of perceptual quality of the image and the OCR performance.
Moreover, we provied (a) hybrid PDF support to extract data from documents containing both scanned and programmatic content, (b) capability to handle skewed documents, (c) multi-lingual support for data extraction from documents with over 50 different languages and (d) extraction service for detecting logos, bar-codes and signatures for downstream document processing such as querying, retrieval etc.
Abhinav Jain
Research Engineer
My research interests include computer vision, machine learning and deep reinforcement learning.
Publications
Simultaneous Optimisation of Image Quality Improvement and Text Content Extraction from Scanned Documents